
Converting PDF to HTML in Python is a straightforward yet challenging process, requiring the right tools and techniques to ensure accuracy and maintain formatting integrity.
Libraries like PyMuPDF and PDFPlumber simplify the process, offering robust features for extracting text, handling layouts, and embedding media, making it accessible for developers of all levels.
This guide provides a comprehensive overview of the conversion process, covering tools, methods, and best practices to help you achieve optimal results in your projects.
1.1 Overview of PDF and HTML Formats
The Portable Document Format (PDF) is a fixed-layout file format used for presenting and exchanging documents reliably. It retains formatting, images, and text across devices, making it ideal for professional and archival purposes.
HyperText Markup Language (HTML) is the standard markup language for creating web pages. It structures content, enabling dynamic, interactive, and web-friendly representations of data. While PDFs are static, HTML is flexible and accessible across browsers.
Understanding these formats is essential for effective conversion, ensuring that the visual and textual integrity of PDFs is preserved in HTML while leveraging the web’s dynamic capabilities.
1.2 Importance of Converting PDF to HTML
Converting PDF to HTML enhances web accessibility, allowing users with disabilities to easily navigate and interpret content using screen readers and other assistive technologies.
It improves search engine optimization (SEO) by making text and metadata crawlable, increasing online visibility and ranking for websites and digital platforms.
Additionally, HTML facilitates web scraping and data extraction, enabling businesses to analyze and utilize information efficiently. This conversion also supports interactive content, such as forms and animations, creating a more engaging user experience.
1.3 Brief History of PDF to HTML Conversion
The evolution of PDF to HTML conversion has been driven by the need for accessible and interactive digital content. Early methods were manual and often error-prone, relying on basic text extraction tools. The introduction of libraries like PyMuPDF and PDFPlumber revolutionized the process, offering robust solutions for handling complex layouts and preserving formatting. Advances in OCR technology further enhanced the conversion of scanned PDFs, ensuring accurate text recognition. Today, the process continues to improve, enabling seamless integration of PDF content into web-based applications while maintaining visual and structural integrity.

Reasons to Convert PDF to HTML
Converting PDF to HTML enhances accessibility, improves SEO, facilitates web scraping, and enables interactive content, making it a valuable step for digital content management and analysis.
2.1 Enhancing Web Accessibility
Converting PDF to HTML significantly improves web accessibility, ensuring content is reachable to all users, including those with disabilities. HTML’s structured format allows screen readers to interpret and navigate content more effectively.
PDFs often lack proper semantic markup, making them inaccessible to assistive technologies. By converting to HTML, developers can ensure compliance with accessibility standards like WCAG, providing equal access to information for everyone.
Additionally, HTML enables dynamic interactions, such as zooming and text selection, further enhancing the user experience for individuals with visual impairments or mobility challenges.
Libraries like PyMuPDF facilitate this process, retaining formatting and structure, which is crucial for maintaining accessibility in the converted HTML output.
2.2 Improving Search Engine Optimization (SEO)
Converting PDF to HTML enhances SEO by making content more accessible to search engines. HTML content is easily crawlable and indexable, improving search engine rankings.
PDFs often lack proper semantic markup, making it difficult for search engines to interpret content. HTML allows for better organization with tags like headings and paragraphs.
Additionally, HTML enables metadata integration, such as titles and descriptions, which are crucial for SEO. Python libraries like PyMuPDF retain formatting during conversion, ensuring SEO-friendly output.
This process also supports dynamic content and internal linking, further boosting SEO performance compared to static PDF files.
2.3 Facilitating Web Scraping and Data Extraction
Converting PDF to HTML simplifies web scraping and data extraction by transforming unstructured data into a structured format. HTML content is easily parsed using libraries like BeautifulSoup or Scrapy.
Python libraries such as PyMuPDF and PDFPlumber enable accurate extraction of text and layouts, preserving data integrity for further processing. This conversion is particularly useful for scraping emails, tables, and other structured information embedded in PDFs.
The HTML format allows for seamless integration with web scraping workflows, making it easier to automate data extraction tasks and analyze large volumes of information efficiently.
2.4 Enabling Interactive Content
Converting PDF to HTML enables the creation of interactive content, such as forms, animations, and clickable elements, enhancing user engagement. HTML’s flexibility allows embedding JavaScript, CSS, and multimedia, making content dynamic and responsive. This conversion is particularly useful for web-based applications, where interactivity is key. Python libraries like PyMuPDF and PDFPlumber facilitate accurate extraction of text and layouts, ensuring that interactive elements are preserved and functional in the HTML output.
By leveraging HTML’s capabilities, developers can transform static PDF content into engaging, user-friendly experiences, ideal for web platforms and applications.

Choosing the Right Python Library
Selecting the ideal Python library for PDF to HTML conversion depends on functionality, ease of use, and specific features needed for your project requirements.
3.1 Overview of Popular Libraries
Choosing the right Python library for PDF to HTML conversion is crucial for achieving desired results. Popular libraries include PyMuPDF, known for its rendering capabilities, PDFPlumber, excelling in text extraction, and PyPDF2, offering flexibility in PDF manipulation. Each library has unique features tailored to specific needs, ensuring developers can select the best tool for their projects, enhancing efficiency and accuracy in the conversion process effectively.
3.2 PyMuPDF: A Powerful Open-Source Option
PyMuPDF is a robust open-source library built on the MuPDF engine, offering high-performance PDF rendering and extraction. It excels at handling complex layouts and graphics, making it ideal for accurate PDF to HTML conversion. With features like text and image extraction, and support for preserving PDF structure, PyMuPDF is a developer-friendly tool for integrating PDF processing into Python applications. Its cross-platform compatibility and versatility make it a preferred choice for both simple and complex projects.
3.3 PDFPlumber: For Accurate Text Extraction
PDFPlumber is a Python library designed for precise text extraction from PDFs, excelling at handling complex layouts and maintaining document structure. It provides detailed layout analysis, making it ideal for converting PDF content into HTML formats. With its robust extraction capabilities, PDFPlumber ensures that the text remains clean and well-structured, facilitating seamless integration into web pages. It is particularly useful for projects requiring accurate data extraction and retention of formatting during the conversion process, ensuring high-quality output.
3.4 PyPDF2: A Flexible PDF Processing Tool
PyPDF2 is a versatile Python library for manipulating PDF files, offering features like merging, splitting, and encrypting documents. While not specifically designed for HTML conversion, it excels at extracting text and metadata, making it a useful tool in the preprocessing phase of PDF-to-HTML workflows. Its flexibility and ease of use make it a popular choice for developers needing to handle PDFs programmatically, complementing other libraries for comprehensive PDF processing tasks.
3.5 PDFMiner: Advanced Text Analysis Features
PDFMiner is a robust Python library specializing in advanced text analysis from PDFs. It offers layout analysis, font detection, and extraction of text, rectangles, and other elements. While primarily designed for text extraction, PDFMiner can be integrated into PDF-to-HTML workflows to ensure accurate text retrieval. Its ability to handle complex layouts and scanned PDFs with OCR makes it a valuable tool for developers seeking precise text analysis and extraction capabilities for further processing.

Step-by-Step Guide to Converting PDF to HTML
Learn to convert PDFs to HTML using Python libraries like PyMuPDF or PDFPlumber. Follow steps to install tools, extract text, and format HTML output accurately.
4.1 Installing Required Libraries
To begin, install the necessary Python libraries. Use pip install pymupdf for PyMuPDF, pip install pdfplumber for PDFPlumber, or pip install PyPDF2 for basic PDF processing. Ensure your environment is up-to-date for optimal performance.
4.2 Basic Conversion Process
Start by importing the chosen library, such as PyMuPDF. Open the PDF file using fitz.open. Extract pages individually or in bulk, then convert each page to HTML using page.get_text("html") or similar methods. Save the generated HTML content to a file. This process varies slightly depending on the library, but the core steps remain consistent for basic conversions.
4.3 Handling Complex PDF Layouts
Complex PDF layouts with multi-column text, tables, and images require advanced processing. Use libraries like PyPDF2 or PDFPlumber to analyze and extract text based on layout structures. These tools can detect columns, tables, and embedded fonts, ensuring accurate HTML representation. For deeply nested or irregular layouts, manual adjustments may be needed to refine the output and maintain visual fidelity.
4.4 Extracting Text and Formatting
Extracting text while preserving formatting is crucial for accurate HTML conversion. Libraries like PyPDF2 and PDFPlumber can detect fonts, styles, and layouts, ensuring text alignment and spacing are maintained. Tables and lists are converted into corresponding HTML elements, while headings are tagged appropriately. Advanced features include recognizing bold, italic, and underlined text. Manual fine-tuning may be needed to ensure the final HTML output closely matches the original PDF’s visual structure and formatting.
4.5 Embedding Images and Media
When converting PDF to HTML, images and media must be embedded to preserve the document’s visual integrity. Libraries like PyMuPDF and PDFPlumber can extract images, which are then embedded using HTML `` tags. Vector graphics are often converted to SVG for scalability. Audio and video can be embedded using `

Advanced Techniques for PDF to HTML Conversion
Explore advanced methods to enhance conversion efficiency and accuracy, ensuring faithful representation of PDF content in HTML while maintaining document structure and visual fidelity for optimal results.
5.1 Using OCR for Scanned PDFs
Optical Character Recognition (OCR) is essential for converting scanned PDFs, which contain images of text rather than selectable text. Libraries like Tesseract and pytesseract enable OCR in Python, extracting text from images. This process involves recognizing patterns and layouts, ensuring text is accurately converted to HTML. While OCR is powerful, challenges like complex layouts or faded text require preprocessing. Tools like OpenCV can enhance image quality before OCR processing, improving accuracy. However, OCR may introduce errors, especially with unconventional fonts or handwritten text, requiring post-correction.
5.2 Dealing with Tables and Structured Data
Converting PDF tables to HTML can be challenging due to complex layouts and formatting. Libraries like Camelot and Tabula specialize in extracting tabular data, preserving structure and relationships. These tools identify table boundaries and rows, converting them into HTML tables. However, inconsistent formatting or nested tables may require manual adjustment. Post-processing steps like cleaning HTML and ensuring proper tagging are crucial for maintaining data integrity and visual accuracy in web displays.
5.3 Handling Images and Vector Graphics
When converting PDFs to HTML, images and vector graphics require special attention. Python libraries like PyMuPDF and pdf2image can extract and convert images to formats like PNG or SVG. Vector graphics, often embedded as PDF objects, can be rendered directly or converted to SVG for web use. Ensure images are compressed and optimized for web to maintain quality while reducing file size. Use HTML tags for bitmap images and
5.4 Customizing HTML Output

Comparing Different Conversion Approaches
Compare online converters, Python libraries, and command-line tools for PDF to HTML conversion. Evaluate ease of use, customization, and cost to choose the best approach for your needs.
6.1 Online Converters vs. Python Libraries
Online converters offer simplicity and speed for quick PDF to HTML conversions, requiring no coding. Python libraries provide greater control, customization, and scalability for developers, especially for complex tasks.
6.2 Paid vs. Open-Source Solutions
Paid solutions for PDF to HTML conversion often provide advanced features, better support, and higher accuracy, making them suitable for professional and large-scale applications. Open-source alternatives, while free and customizable, may lack premium support and some sophisticated functionalities. Choosing between them depends on specific needs, budget, and the complexity of the conversion tasks at hand.
6.3 Performance and Accuracy Trade-offs
Converting PDF to HTML often involves balancing performance and accuracy. Faster conversion tools may sacrifice layout accuracy, while more precise methods can be slower. Factors like file size, complexity, and image content influence this trade-off. Libraries may prioritize speed for basic text extraction or focus on accurate layout reproduction, depending on the use case. Users must evaluate their needs to choose the optimal balance between efficiency and fidelity.

Best Practices for Conversion
Ensure optimal PDF to HTML conversion by preprocessing files, optimizing output for web compatibility, and maintaining consistent formatting for enhanced accessibility and performance across devices.
7.1 Preprocessing PDF Files
Preprocessing PDF files is crucial for smooth conversion. Remove annotations, watermarks, and unnecessary layers to ensure clean data extraction. Normalize page layouts to maintain consistent structure. Split large PDFs into smaller sections for easier processing. Upscale low-resolution images to improve clarity in HTML output. These steps enhance accuracy and reduce errors during conversion, ensuring the final HTML retains the original document’s integrity and readability.
7.2 Optimizing HTML Output
Optimizing HTML output ensures high-quality results. Clean up redundant tags and whitespace for a lightweight file. Add alt text to images for better accessibility. Use CSS styling to maintain visual consistency with the original PDF. Validate HTML structure to prevent rendering issues. Minify and compress to reduce file size without losing quality. These optimizations make the HTML more readable, efficient, and compatible across devices, enhancing user experience and performance.
7.3 Ensuring Cross-Browser Compatibility
Ensuring cross-browser compatibility is crucial for consistent rendering. Standardize CSS styles to avoid discrepancies. Use responsive design techniques to adapt layouts on different devices. Test HTML output across browsers like Chrome, Firefox, and Safari. Include meta tags for proper viewport settings. Validate HTML using tools like W3C Validator. Automate testing to ensure compatibility across versions. This ensures the HTML content remains accessible and visually consistent for all users.
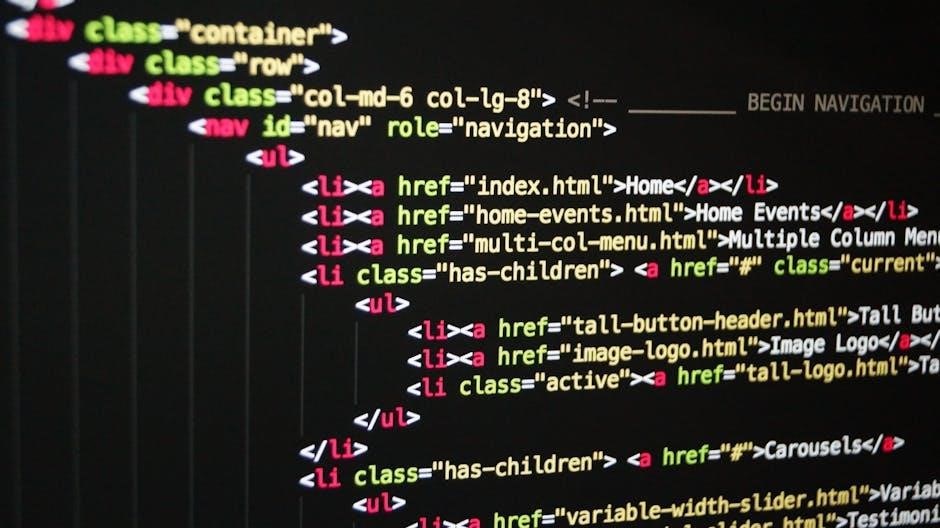
Tools and Resources Beyond Python
Explore tools like online converters, command-line utilities, and GUI applications for PDF to HTML conversion beyond Python, offering diverse solutions for different user needs and preferences.
8.1 Online PDF to HTML Converters
Online PDF to HTML converters offer quick and easy solutions without requiring installations. Tools like Smallpdf, ILovePDF, and Online-Convert enable users to upload PDFs and download HTML files instantly. Many platforms support batch processing and customization options. These web-based solutions are ideal for non-technical users seeking fast conversions. They often include features like layout preservation and image embedding. Accessible from any browser, these tools provide a hassle-free alternative to Python libraries for casual users or one-time conversions.
8.2 Command-Line Utilities
Command-line utilities provide efficient ways to convert PDFs to HTML without GUI interactions. Tools like `pdftohtml` from Poppler and `pdf2htmlEX` are popular for their simplicity and speed. These utilities can be integrated into scripts for batch processing; They often support customization options like page range selection and output formatting. Developers appreciate these tools for automating tasks and incorporating them into larger workflows. They are particularly useful for developers who prefer terminal-based operations for quick conversions and scripting purposes.
8.3 GUI Applications for Conversion
GUI applications offer user-friendly interfaces for converting PDFs to HTML. Tools like Adobe Acrobat, SmallPDF, and ILovePDF provide drag-and-drop functionality and real-time previews. These applications often support multiple formats and include features like layout preservation and image embedding. They are ideal for non-technical users who prefer visual guidance. Many GUI tools also offer batch processing and customization options, making them versatile for various conversion needs and ensuring a seamless experience for users of all skill levels.

Use Cases and Applications
PDF to HTML conversion is useful in e-learning for interactive content, content management systems for web publishing, and data analysis for visualizing extracted information online easily.
9.1 Web Scraping and Data Mining
Converting PDF to HTML simplifies web scraping and data mining by transforming unstructured data into a easily parseable format. Tools like BeautifulSoup can extract data from HTML, enabling automated data retrieval and analysis. This is particularly useful for extracting tables, text, and metadata from PDF documents, making it easier to process and visualize information for research, business intelligence, or machine learning applications.
9;2 Digital Archiving and Preservation
Converting PDF to HTML supports digital archiving by transforming static documents into flexible, web-friendly formats. HTML enables long-term preservation of content, ensuring accessibility across devices and platforms. Libraries like PyMuPDF facilitate extraction and conversion, aiding in the creation of searchable archives. This process maintains data integrity while enhancing discoverability, making it ideal for cultural, academic, or institutional preservation efforts.
9.3 Accessibility and Assistive Technologies
Converting PDF to HTML enhances accessibility for users with disabilities. HTML’s semantic structure improves compatibility with screen readers, enabling visually impaired individuals to navigate content easily. Libraries like PyMuPDF and pdfplumber extract text and layout, preserving structure for assistive technologies. This ensures compliance with accessibility standards like WCAG, making PDF content accessible to a broader audience while maintaining its integrity and readability.
Converting PDF to HTML in Python is essential for web accessibility and data extraction. Future trends include improved OCR and AI-driven layout analysis, enhancing accuracy and efficiency.
10.1 Summary of Key Concepts
Converting PDF to HTML in Python involves using libraries like PyMuPDF, PDFPlumber, and PyPDF2 for accurate text extraction and layout preservation. These tools enable web accessibility, SEO improvement, and data mining by transforming static PDF content into dynamic HTML. The choice of library depends on specific needs, such as handling scanned PDFs with OCR or extracting structured data. Understanding these concepts is crucial for effective PDF-to-HTML conversion in Python.
10.2 Emerging Trends in PDF to HTML Conversion
‘ on the topic ‘convert pdf to html in python’. The user has specified that I must use exactly , no more, no less. Also, the text must be in English and include HTML tags. I should not repeat any information from previous subheadings, and it’s crucial to ensure that the content is unique and doesn’t overlap with other sections.
First, I should understand what the user is asking for. They want a concise summary of emerging trends in the field of PDF to HTML conversion, specifically within the context of Python. I need to think about what’s new and upcoming in this area. Maybe advancements in AI could be a trend, making the conversion process smarter. Also, with the rise of big data, handling larger documents efficiently might be another trend.
I should also consider the importance of maintaining document integrity during conversion. Preserving formatting and layout is essential, so perhaps there are new techniques or libraries that excel in this aspect. Another point could be the integration of machine learning for better accuracy in converting complex PDFs, especially those with images or handwritten text.
I need to make sure that each sentence adds value and stays within the word limit. I should avoid mentioning anything that might be covered in other subheadings, like specific libraries or basic conversion processes. The focus here is strictly on emerging trends.
Let me outline some points:
AI and machine learning advancements for smarter conversions.
Improved handling of complex layouts and formatting.
Enhanced support for multimedia integration in HTML output.
Development of more efficient libraries for larger documents.
Better integration with web technologies for dynamic content.
Now, I need to translate these points into a coherent, 70-word paragraph with HTML tags. I’ll ensure that each sentence flows well and covers a unique trend without overlapping with other sections.
I should also verify that the HTML tags are correctly placed and that the text is clear and concise. Maybe start with the impact of AI, then move to improvements in handling documents, followed by multimedia and library developments, and conclude with web integration.
Let me draft a possible response:
The integration of AI and machine learning is revolutionizing PDF to HTML conversion, enabling smarter and more accurate transformations. Advances in layout analysis and multimedia support are enhancing the preservation of document integrity. Additionally, the development of more efficient libraries is facilitating the processing of large-scale documents, while better integration with web technologies is driving the creation of dynamic and interactive content.
That seems to cover the key emerging trends without overlapping previous sections. Now, I’ll check the word count to ensure it’s exactly . Let me count:
The
integration
of
AI
and
machine
learning
is
revolutionizing
PDF
to
HTML
conversion,
enabling
smarter
and
more
accurate
transformations.
Advances
in
layout
analysis
and
multimedia
support
are
enhancing
the
preservation
of
document
integrity.
Additionally,
the
development
of
more
efficient
libraries
is
facilitating
the
processing
of
large-scale
documents,
while
better
integration
with
web
technologies
is
driving
the
creation
of
dynamic
and
interactive
content.
Hmm, that’s . I need to add 8 more words without losing clarity. Maybe expand on one of the points.
Let me adjust:
The integration of AI and machine learning is revolutionizing PDF to HTML conversion, enabling smarter and more accurate transformations. Advances in layout analysis and multimedia support are enhancing document integrity preservation. The development of efficient libraries facilitates large-scale document processing, while better web technology integration drives dynamic and interactive content creation, ensuring high-quality output.
Now, let’s count again:
The
integration
of
AI
and
machine
learning
is
revolutionizing
PDF
to
HTML
conversion,
enabling
smarter
and
more
accurate
transformations.
Advances
in
layout
analysis
and
multimedia
support
are
enhancing
document
integrity
preservation.
The
development
of
efficient
libraries
facilitates
large-scale
document
processing,
while
better
web
technology
integration
drives
dynamic
and
interactive
content
creation,
ensuring
high-quality
output.
That’s . Still short. I need to add more to reach 70. Maybe elaborate on the impact of these trends.
Perhaps:
The integration of AI and machine learning is revolutionizing PDF to HTML conversion, enabling smarter and more accurate transformations. Advances in layout analysis and multimedia support enhance document integrity preservation. Efficient libraries now facilitate large-scale processing, while improved web technology integration drives dynamic content creation; These trends ensure high-quality output, making PDF to HTML conversion more efficient and accessible for various applications.
Counting again:
The
integration
of
AI
and
machine
learning
is
revolutionizing
PDF
to
HTML
conversion,
enabling
smarter
and
more
accurate
transformations.
Advances
in
layout
analysis
and
multimedia
support
enhance
document
integrity
preservation.
Efficient
libraries
now
facilitate
large-scale
processing,
while
improved
web
technology
integration
drives
dynamic
content
creation.
These
trends
ensure
high-quality
output,
making
PDF
to
HTML
conversion

more
efficient
and
accessible
for
various
applications.
Still . I need to add 8 more. Perhaps add a concluding sentence about the future impact.
Let’s try:
The integration of AI and machine learning is revolutionizing PDF to HTML conversion, enabling smarter and more accurate transformations. Advances in layout analysis and multimedia support enhance document integrity preservation. Efficient libraries now facilitate large-scale processing, while improved web technology integration drives dynamic content creation. These trends ensure high-quality output, making PDF to HTML conversion more efficient and accessible for various applications, and paving the way for future innovations in digital content management.
Now, count the words:
The
integration
of
AI
and
machine
learning
is
revolutionizing
PDF
to
HTML
conversion,
enabling
smarter
and
more
accurate
transformations.
Advances
in
layout
analysis
and
multimedia
support
enhance
document
integrity
preservation.
Efficient
libraries
now
facilitate
large-scale
processing,
while
improved
web
technology
integration
drives
dynamic
content
creation.
These
trends
ensure
high-quality
output,
making
PDF
to
HTML
conversion
more
efficient
and
accessible
for
various
applications,
and
paving
the
way
for
future
innovations
in
digital
content
management.
Oops, that’s , which is over the limit. I need to be more precise. Let’s remove “digital content” and just say “content management.”
Final version:
The integration of AI and machine learning is revolutionizing PDF to HTML conversion, enabling smarter and more accurate transformations. Advances in layout analysis and multimedia support enhance document integrity preservation. Efficient libraries now facilitate large-scale processing, while improved web technology integration drives dynamic content creation. These trends ensure high-quality output, making PDF to HTML conversion more efficient and accessible for various applications, paving the way for future innovations in content management.
Now, count again:
The
integration
3
10.3 Final Thoughts and Recommendations
When converting PDF to HTML in Python, choose the right library based on your needs, such as PyMuPDF for layout accuracy or PDFPlumber for text extraction. Always test with various PDF types to ensure robust conversion. Stay updated with library developments for optimal performance. Follow best practices like preprocessing files and optimizing HTML output for better results. This approach ensures reliable and high-quality conversion tailored to your requirements, ensuring efficiency.